История
Первые DSP появились в 1970-х годах. Эти процессоры стали логичным развитием специализированных аналогово-цифровых устройств, предназначенных для обработки речи, прежде всего её кодирования и фильтрации (прорыв в соответствующих научно-технических отраслях стал возможен благодаря спросу на эти технологии в годы Второй Мировой войны). Трудоемкость и сложность разработки устройств под каждую возникающую задачу, а также успехи в развитии электронной базы (широкое распространение технологии MOSFET) и математических алгоритмов (БПФ, цифровая фильтрация) привели к возможности создания универсальных, т.е. программируемых, цифровых процессоров, которые могли быть с помощью программ адаптированы для широкого класса задач. Адаптируемость на практике означала снижение стоимости разработок, сокращение времени выхода на рынок (time-to-market), возможность послепродажного обновления алгоритма для устранения ошибок, возможность поддержки новых требований пользователей. Во многих случаях эти возможности с лихвой компенсировали ухудшение производительности по сравнению со специальными ускорителями.
Рис. 1 Первый крупный успех DSP: планшет Speak&Spell (Texas Instruments, 1978)Рис. 2 С момента появления стандарта GSM DSP являются обязательным компонентом мобильных сетей
Из-за необходимости обработки в реальном времени и экономии электроэнергии DSP сильно отличались от процессоров общего назначения. В каком-то смысле они были первым примером программируемых вычислительных ускорителей, т.е. процессоров, максимально эффективно решающих определённый класс задач.
Выравнивание проигрывания аудио
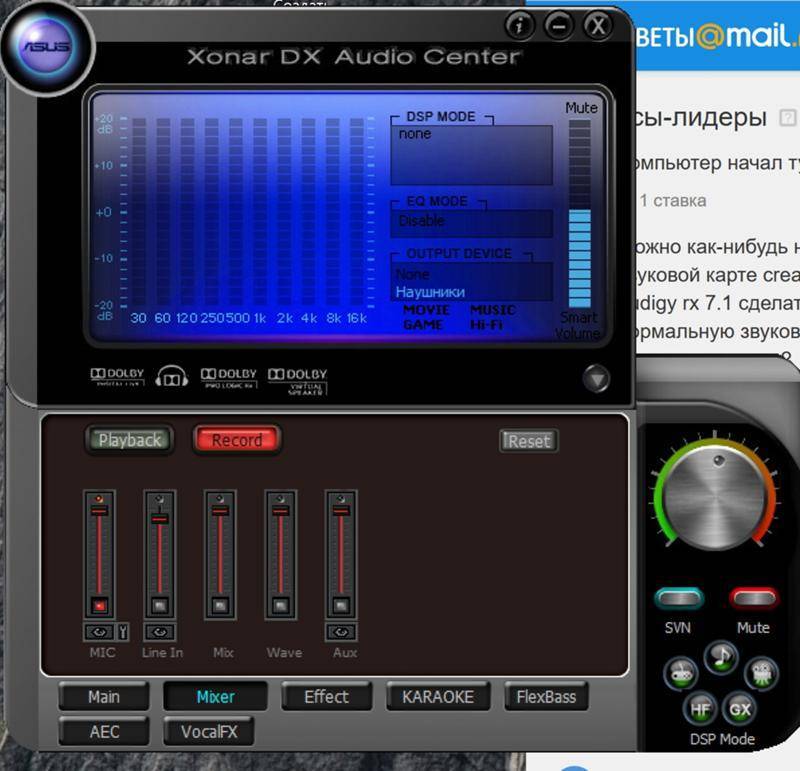
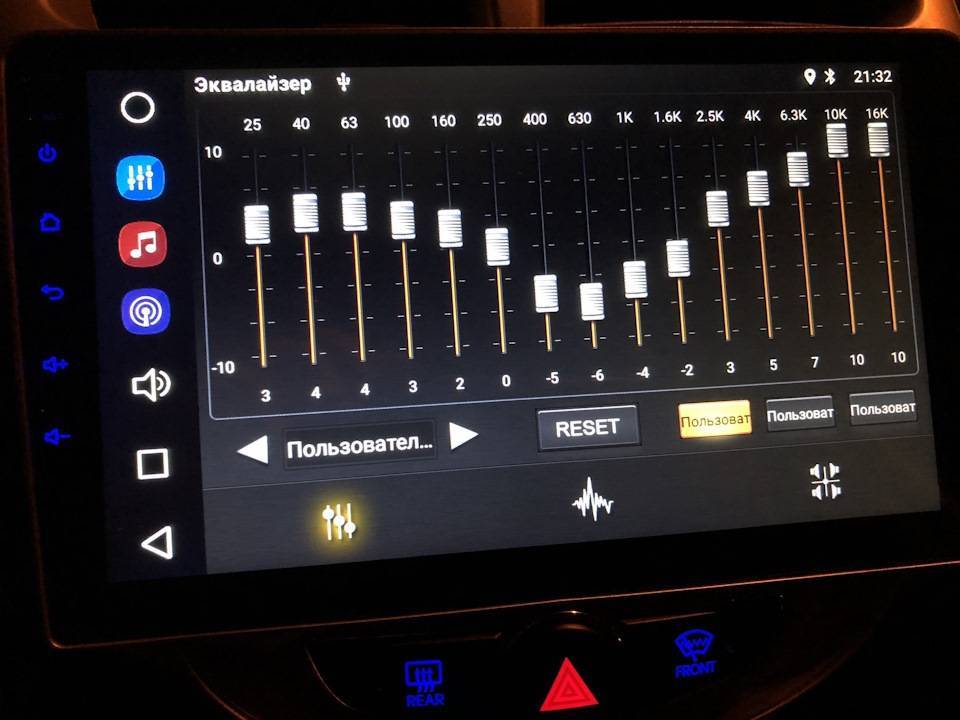
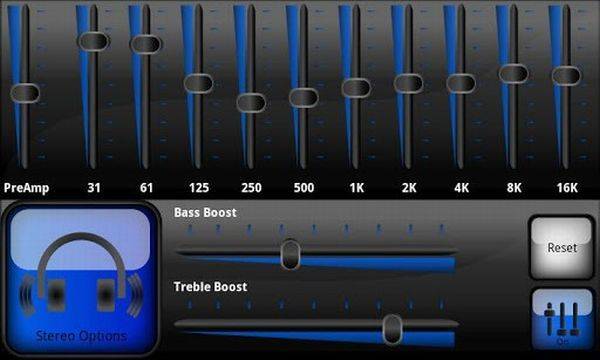
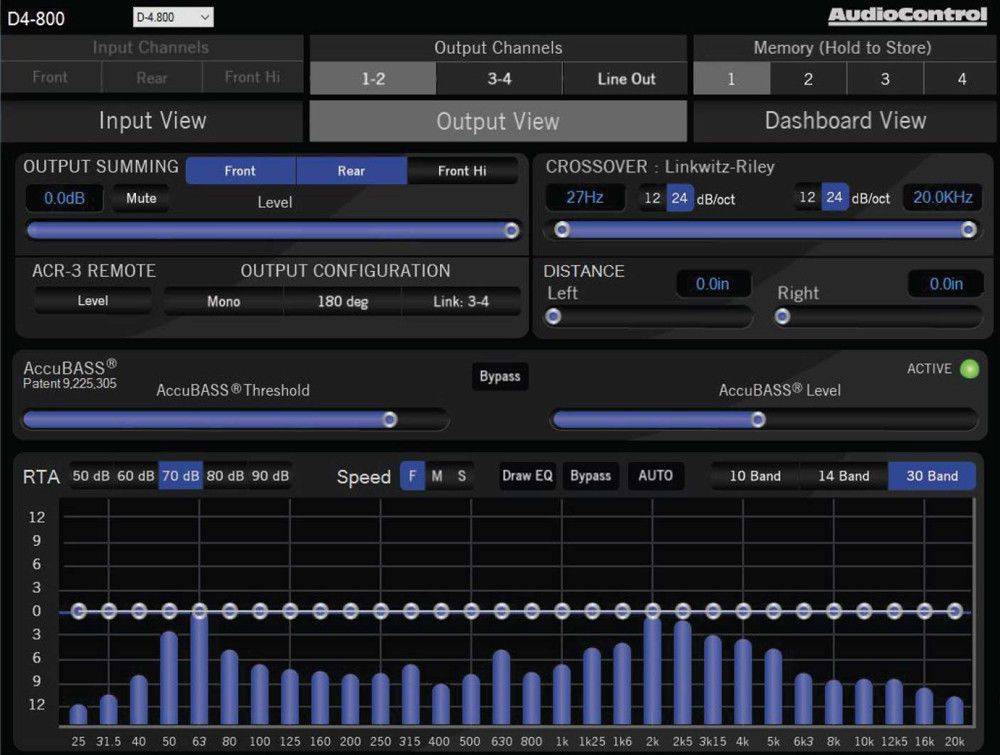
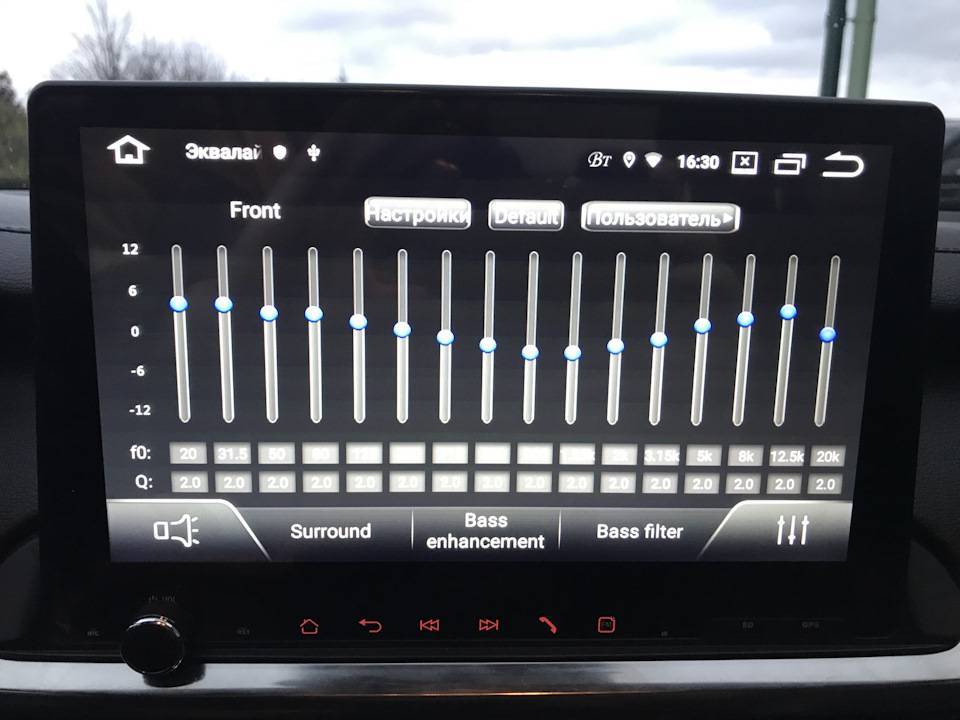
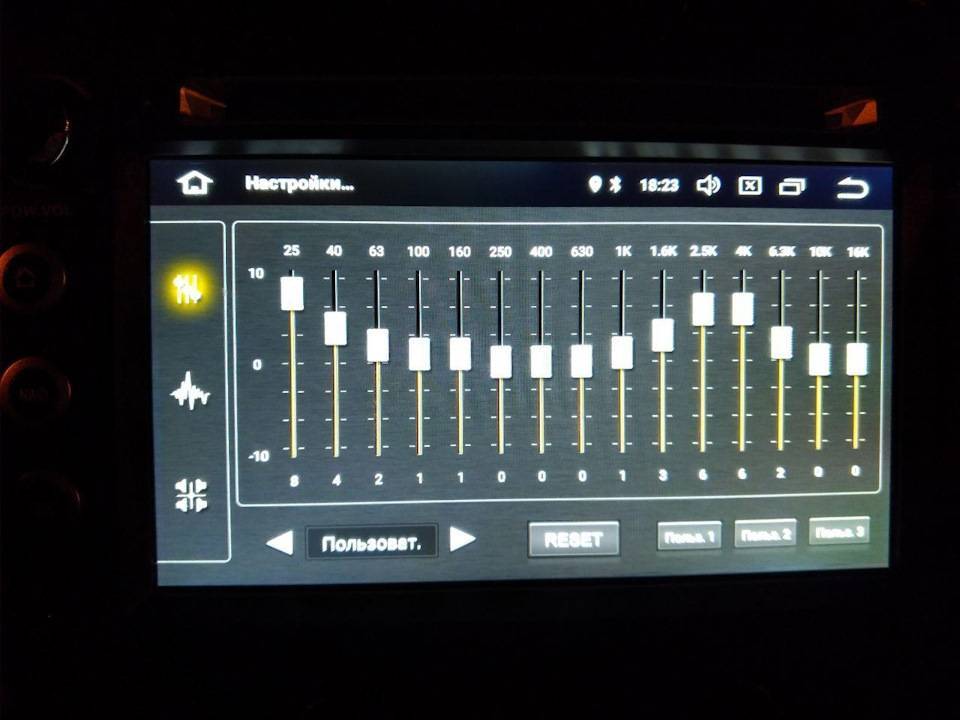
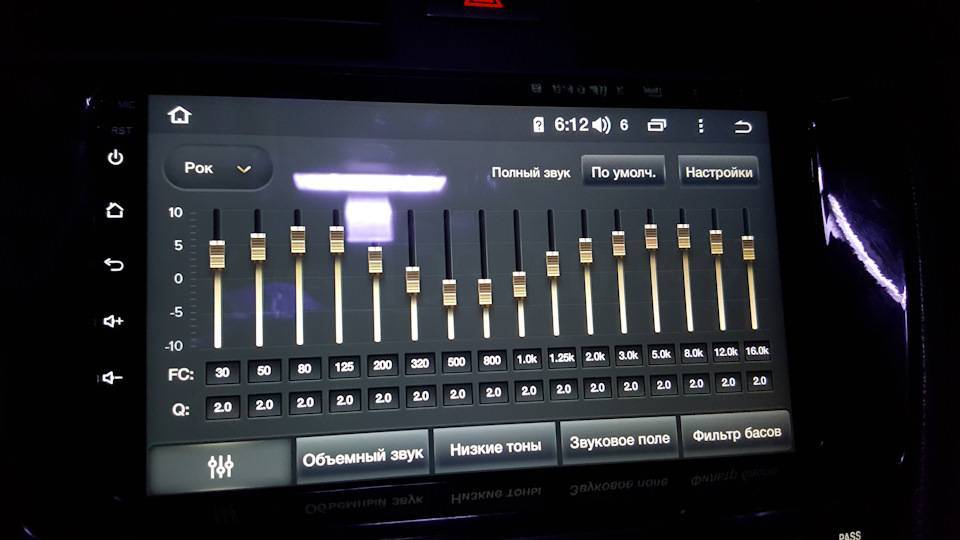
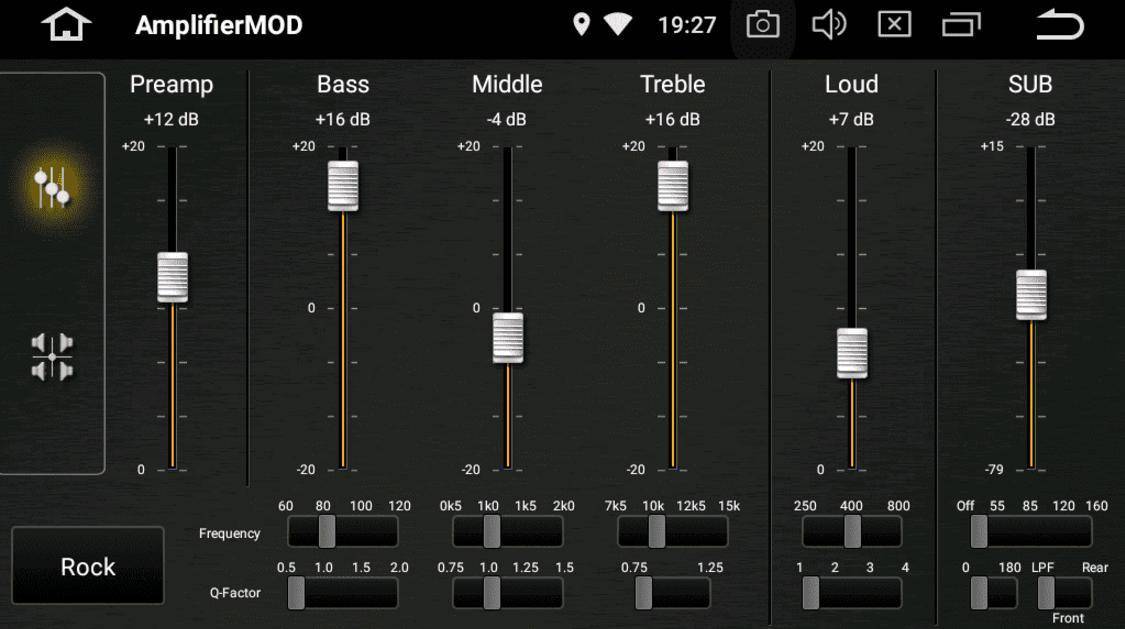
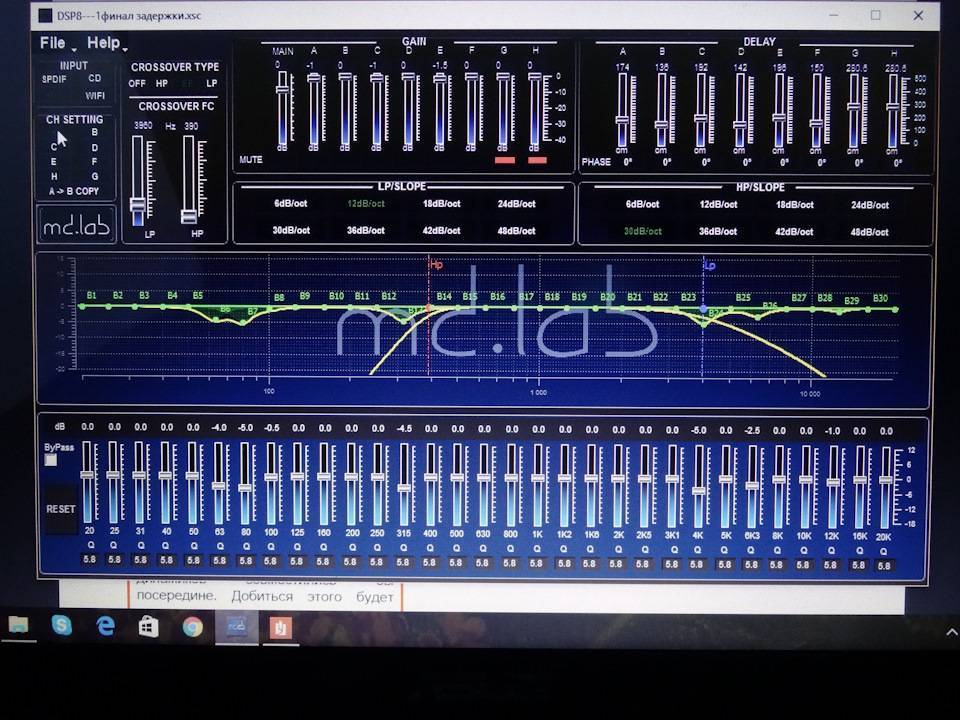
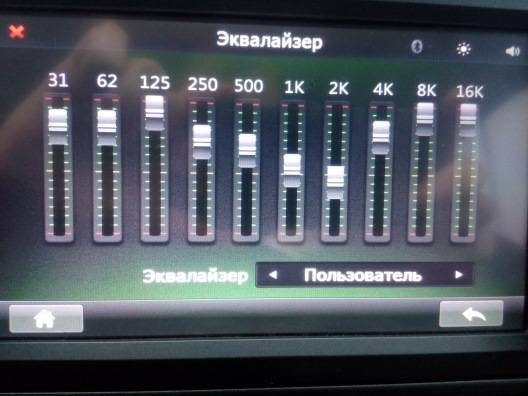
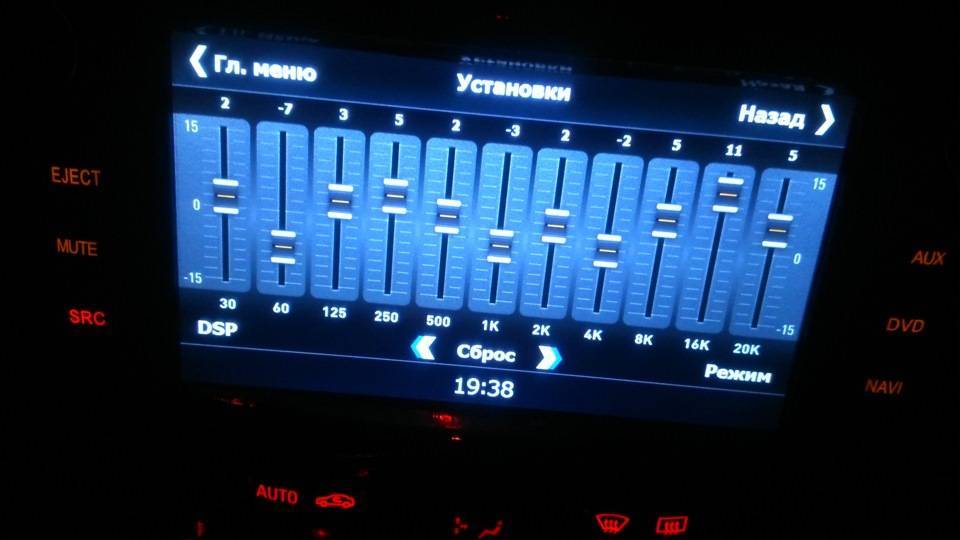
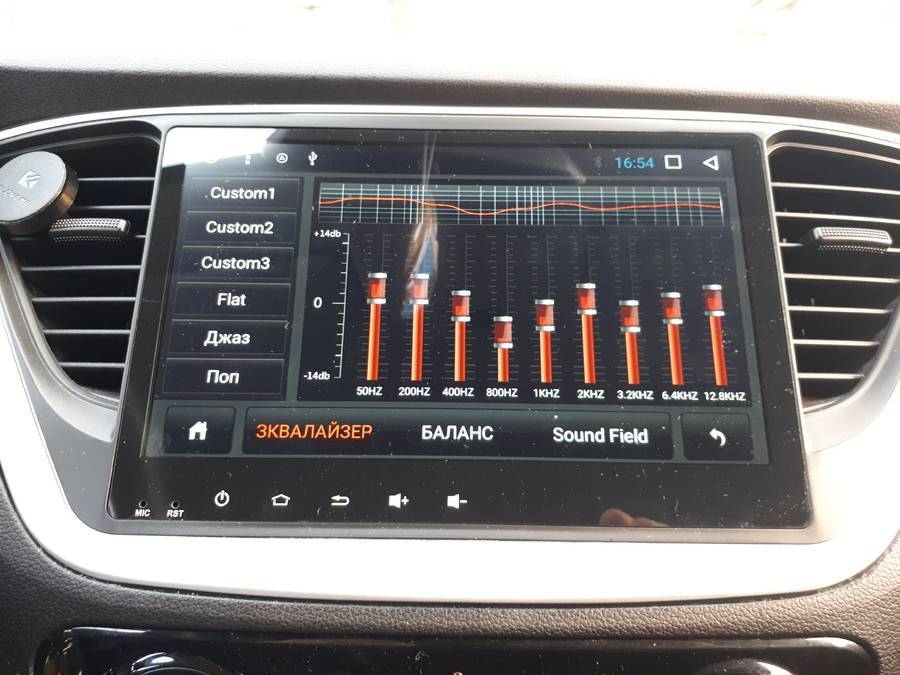
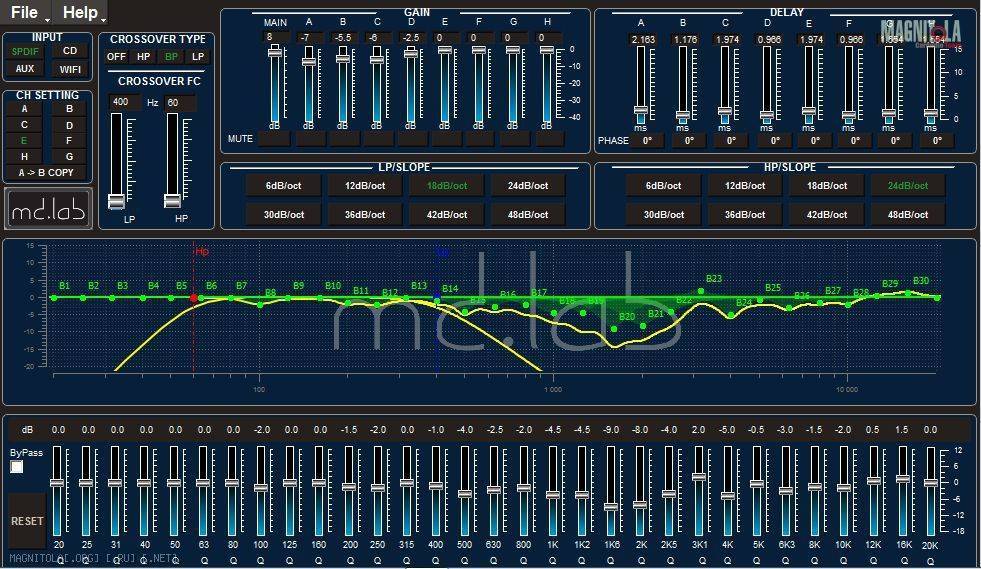
Некоторые головные устройства включают в себя простые настройки низких, высоких и средних частот, но эквалайзеры позволяют еще эффективнее оптимизировать звук. В системе, которая включает усилитель , эквалайзер находится между головным устройством и усилителем; он позволяет вам увеличивать или сокращать определенные частоты звука.
Существует несколько различных типов эквалайзеров, каждый из которых имеет свои преимущества:
- Графические эквалайзеры имеют фиксированную полосу пропускания, содержат слайдеры, которые позволяют выполнять точные настройки.
- Параметрические эквалайзеры обеспечивают еще больший контроль, поскольку позволяют регулировать ширину и центральную точку каждого частотного диапазона.
Эквалайзер – предварительный усилитель Carbon CDA-105E - Усилители EQ представляют собой комбинацию эквалайзера и усилителя. Они обычно не такие мощные, как большинство хороших усилителей, но использование одного такого устройства намного более простое, нежели работа с пассивным эквалайзером и автономным усилителем.
- Аналоговые эквалайзеры используют физические циферблаты или слайдеры для обеспечения точного управления настройками частоты.
- Цифровые эквалайзеры не имеют физических элементов управления, поэтому они часто могут сохранять настройки для различных профилей частот.
Архитектура DSP
Специфика решаемых задач оказывает существенное влияние на архитектуру и системное ПО для DSP. По словам Jennifer Eyre, аналитика исследовательского центра BDTI, “архитектура DSP формируется теми задачами, которые на них считаются” (“Architecture of DSP is molded by algorithms”, из “Evolution of DSP Processors”). Перечислим особенности таких задач:
Практически бесконечный параллелизм уровня команд (ILP, Instruction Level Parallelism)
Большинство алгоритмов (свертка, быстрое преобразование Фурье, вычисления с комплексными числами) сводятся к выполнению операций сложения и умножения над плотными массивами данных
Вычисление производятся на встроенных системах, с жёсткими требованиями по энергопотреблению
Таким образом, основными целями являются максимальное использование присущего задачам параллелизма и снижение энергопотребления при выполнении циклов.
Для использования ILP используются различные техники:
Векторные инструкции (SIMD, Single Instruction Multiple Data)
Сложные инструкции (CISC, Complex Instruction Set Computer):
Составные математические операции (умножение и вычитание с накоплением, гистограммы, спецфункции, комплексные вычисления)
Операции умножения со сдвигом (для арифметики с фиксированной точкой)
Широкий набор режимов адресации (с шагом, с пре- и пост-инкрементом, циклическим обходом и пр.)
Алгоритмо-специфические операции (например подсчёт контрольных сумм сетевых пакетов, криптография, аудио-видео декодеры)
Расширяемые системы команд (в IP-продуктах Ceva и Tensillica)
Сильно расслоенная память (для выдачи нескольких параллельных загрузок за такт или индексных обращений в память типа scatter/gather)
Избавление от задержек, вызываемых ветвлениями:
Поддержка предикатного выполнения для всех команд процессора (или подавляющего большинства)
Процессорные хинты (специальные инструкции для предзагрузки данных)
Слоты задержки
Быстрые циклы (zero-overhead loops)
Вынесение наиболее вычислительно-ёмких алгоритмов (алгоритм Витерби, БПФ, QR-разложение, нейросетевые вычисления) на встроенные ускорители (т.н. fixed function units)
-
Ускорение продолжительных операций с памятью с помощью специальных блоков прямого доступа в память (DMA), с поддержкой произвольных 2D/3D-шагов



Для снижения же энергопотребления используются
Переход от действительных чисел на арифметику с фиксированной точкой
Нестандартные типы данных (например 20- и 40-битные целые)
Упорядоченные (in-order) вычисления, отсутствие спекулятивности (speculation) и внеочередного выполнения (out-of-order)
Явное формирование параллельно исполняемых пакетов инструкций компилятором (VLIW)
Отсутствие отслеживания процессором зависимостей между инструкциями и перенос ответственности за точное планирование инструкций на компилятор (exposed pipeline)
Отсутствие кэшей
Прямое обращение в глобальную DRAM-память приведёт к остановке процессора для выполнения транзакции
Вместо instruction- и data-кэшей используется небольшая (до 1 Мбайта) быстрая SRAM-память, т.н. scratchpad или Tightly Coupled Memory, загрузками в которую явно управляет программист
-
Для упрощения таких загрузок часто используются оверлеи – специальный механизм разбиения программы на независимые участки, которые могут по требованию динамически подгружаться в TCM, вытесняя друг друга
Вместо таблиц предсказания ветвлений (branch target buffer, BTB) в DSP используются различные техники для амортизации ветвлений (слоты задержки, хинты, быстрые циклы)
Кластерные регистровые файлы (т.е. разбиение регистрового файла на блоки, регистры которых не могут использоваться вместе в одной инструкции)
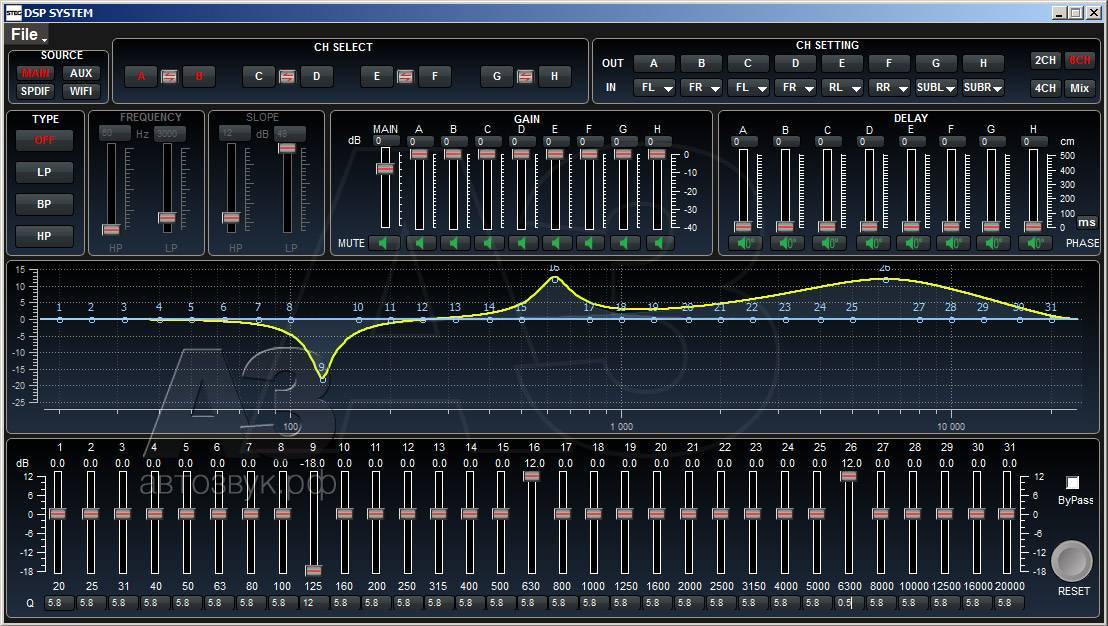
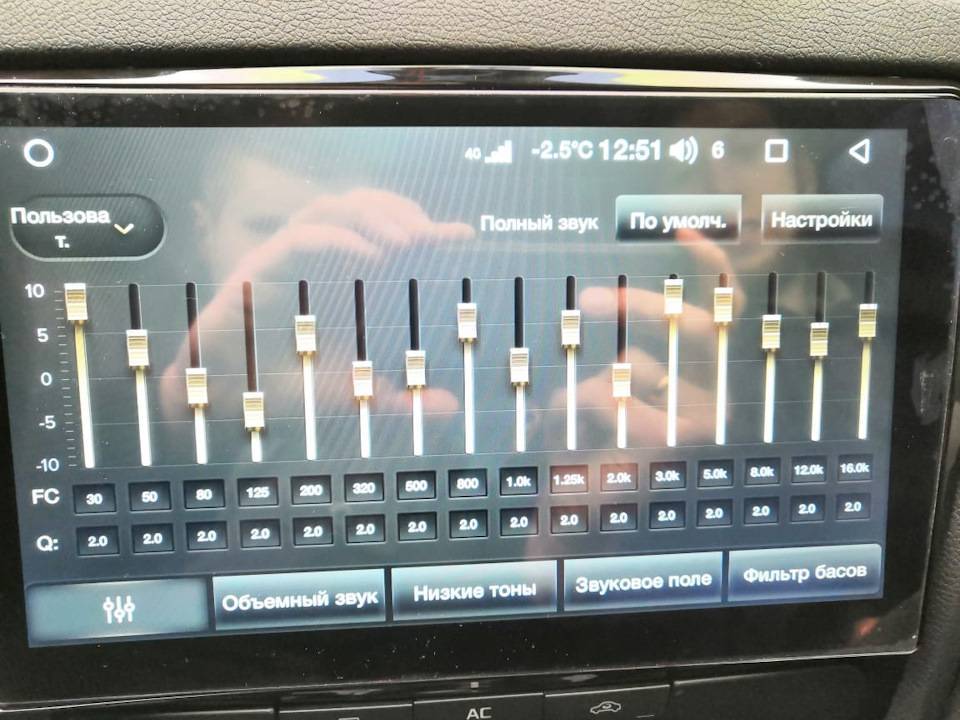
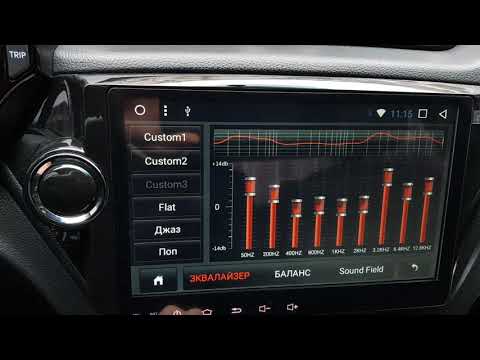
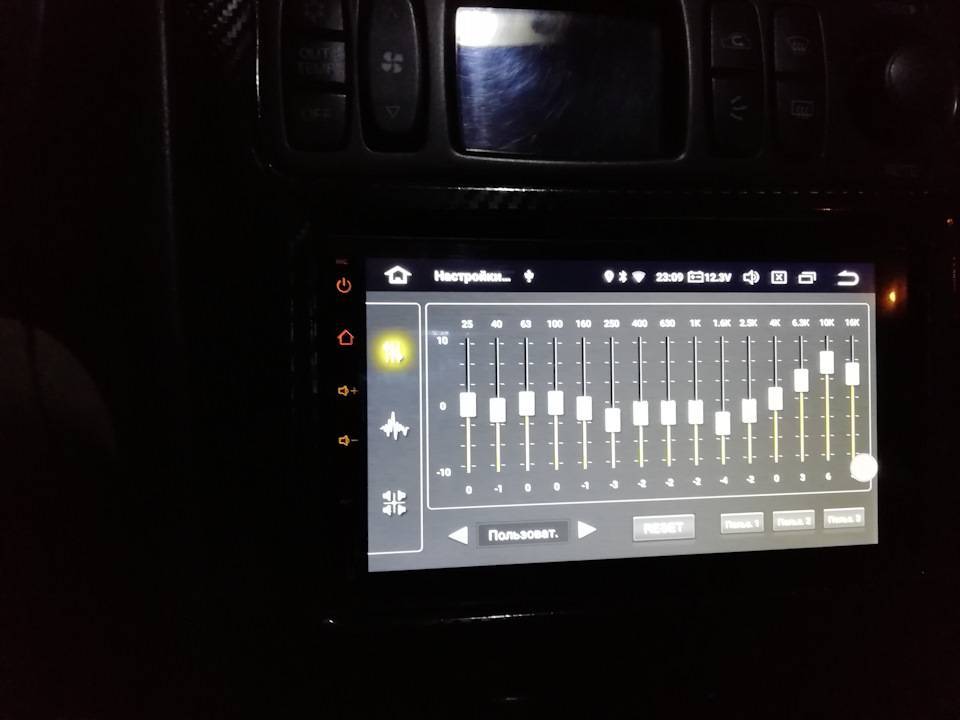

В процессорах общего назначения каждое из указанных решений привело бы к фатальному ухудшению производительности и удобства работы, но в случае DSP особенности применения снимают эту проблему.
Некоторые из указанных подходов можно видеть ниже на примере кода для процессора Texas Instruments:
В частности можно видеть
инструкцию быстрого цикла , сочетающую в себе декремент индекса цикла, сравнение с 0 и условный переход
явное указание пареллелизма с помощью лексемы
явные задержки инструкций с помощью
использование слотов задержки
Об авторе
Юрий Грибов, Senior Engineer, System-on-Chip SW Team, Исследовательский центр Samsung
Автор выражает большую признательность рецензентам из Исследовательского центра Samsung: Алексею Пущину, Михаилу Черкашину и Павлу Копылу.
Компания Samsung выпускает мобильные системы на кристалле Exynos со встроенными DSP и NPU. Они используются, например, для обработки изображений с камеры смартфона. В московском Исследовательском центре Samsung разрабатывают state-of-the-art компиляторы для таких устройств, и мы активно ищем людей в нашу команду. Прямо сейчас в нашем центре открыто несколько вакансий для соискателей разного уровня подготовки: от стажеров до разработчиков сениор-уровня. Узнать подробнее о работе и вакансиях нашего отдела можно в интервью моего руководителя на Хабре.


→ Моя страница на Github